Trong thế giới toán học và khoa học dữ liệu, thuật ngữ “gradient” thường xuyên xuất hiện. Vậy Gradient Là Gì Toán Học? Bài viết này của THPT Hồng Ngự 1 sẽ cung cấp một cái nhìn toàn diện về gradient, từ định nghĩa cơ bản đến các ứng dụng thực tế, giúp bạn hiểu rõ hơn về khái niệm quan trọng này.
Gradient Boosting là một thuật toán học máy mạnh mẽ, sử dụng kỹ thuật học tập tổ hợp (ensemble learning) để tạo ra các dự đoán chính xác bằng cách kết hợp nhiều cây quyết định (decision trees) thành một mô hình duy nhất. Chúng ta hãy cùng tìm hiểu sâu hơn về thuật toán này và các khái niệm liên quan.
1. Gradient Boosting Là Gì?
Gradient Boosting là một thuật toán học máy mạnh mẽ theo hướng học tập tổ hợp (ensemble learning), cho phép tạo ra các dự đoán chính xác bằng cách kết hợp nhiều cây quyết định (decision trees) thành một mô hình duy nhất. Thuật toán này được giới thiệu bởi Jerome Friedman, hoạt động dựa trên nguyên tắc mỗi mô hình cơ sở sẽ học từ sai sót của mô hình trước đó. Qua từng vòng lặp, các mô hình mới dần điều chỉnh lỗi và cải thiện khả năng dự đoán. Nhờ khả năng nhận diện các mẫu phức tạp trong dữ liệu, Gradient Boosting đặc biệt hiệu quả trong các nhiệm vụ dự đoán.
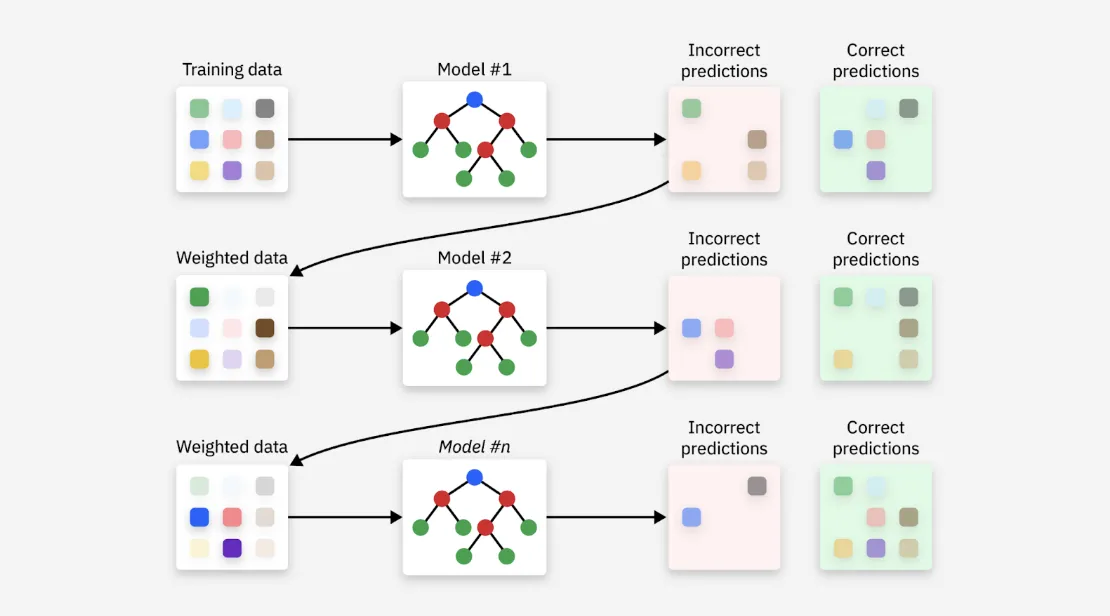 Gradient Boosting
Gradient Boosting
2. Học Tập Tổ Hợp (Ensemble Learning) và Kỹ Thuật Tăng Cường (Boosting)
Học tập tổ hợp (ensemble learning) là một phương pháp trong học máy, kết hợp nhiều mô hình hoặc thuật toán nhằm nâng cao hiệu quả dự đoán. Hai kỹ thuật phổ biến trong phương pháp này là bagging và boosting. Bagging huấn luyện nhiều mô hình trên các tập dữ liệu con khác nhau với yếu tố ngẫu nhiên, giúp giảm phương sai (variance) bằng cách trung bình hóa sai số của từng mô hình. Một ví dụ tiêu biểu của phương pháp này là Random Forests.
Ngược lại, Boosting là kỹ thuật huấn luyện các mô hình theo cách tuần tự, trong đó mỗi mô hình mới được thiết kế để sửa lỗi của mô hình trước. Phương pháp này gán trọng số cao hơn cho các điểm dữ liệu bị phân loại sai ở vòng trước, giúp các mô hình sau tập trung vào những trường hợp khó và từ đó cải thiện hiệu suất tổng thể. AdaBoost, được xem là thuật toán boosting khả thi đầu tiên, là ví dụ điển hình cho phương pháp này.
Cả Bagging và Boosting đều giúp tối ưu hóa sự đánh đổi giữa độ chệch (bias) và phương sai (variance), góp phần cải thiện hiệu năng mô hình. Những kỹ thuật này được ứng dụng rộng rãi trong học máy để cải thiện độ chính xác của mô hình, đặc biệt là trong các bài toán có dữ liệu phức tạp hoặc nhiễu. Bằng cách kết hợp nhiều mô hình, phương pháp học tập tổ hợp (ensemble learning) giúp vượt qua những giới hạn của từng mô hình đơn lẻ.
3. Cách Gradient Boosting Hoạt Động?
Gradient Boosting là một kỹ thuật học máy kết hợp nhiều mô hình dự đoán yếu (weak prediction models) thành một hệ thống tổng hợp. Các mô hình này thường là cây quyết định (decision trees), được huấn luyện tuần tự nhằm giảm lỗi xuống mức tối thiểu và cải thiện độ chính xác. Nhờ việc kết hợp nhiều cây hồi quy (decision tree regressors) hoặc cây phân loại (decision tree classifiers), Gradient Boosting có thể nắm bắt hiệu quả các mối quan hệ phức tạp giữa các đặc trưng (features).
Một trong những điểm mạnh của Gradient Boosting là khả năng tối thiểu hóa hàm mất mát (loss function) một cách lặp đi lặp lại qua từng bước huấn luyện, từ đó cải thiện độ chính xác của dự đoán. Tuy nhiên, kỹ thuật này cũng dễ gặp phải hiện tượng quá khớp (overfitting) – khi mô hình học quá kỹ dữ liệu huấn luyện và khó áp dụng cho dữ liệu mới. Để hạn chế tình trạng này, cần tinh chỉnh các siêu tham số (hyperparameters), theo dõi hiệu suất mô hình trong quá trình huấn luyện, và áp dụng các kỹ thuật như chuẩn hoá (regularization), cắt tỉa mô hình (pruning) hoặc dừng sớm (early stopping).
Sai số bình phương trung bình (Mean Squared Error – MSE) là một hàm mất mát thường dùng để đánh giá mức độ chênh lệch giữa dự đoán của mô hình và giá trị thực tế. MSE được tính bằng trung bình cộng của bình phương sai lệch giữa giá trị dự đoán và giá trị thực tế, theo công thức:
Trong đó:
- yᵢ là giá trị thực tế
- pᵢ là giá trị dự đoán
- n là số lần quan sát
Về bản chất, MSE đo lường mức độ khác biệt giữa các giá trị mô hình dự đoán và giá trị thực trong bài toán hồi quy (regression). Bằng cách bình phương sai số, MSE đảm bảo rằng cả sai số dương và âm đều được tính đến, đồng thời ưu tiên xử lý các sai số lớn. Nhìn chung, giá trị MSE càng thấp thì dự đoán càng chính xác. Tuy nhiên, trong thực tế luôn tồn tại độ ngẫu nhiên nhất định trong dữ liệu nên việc đạt MSE bằng 0 là rất khó và thường phản ánh dấu hiệu của hiện tượng quá khớp (overfitting). Do đó, việc so sánh giá trị MSE giữa các mô hình hoặc theo thời gian là cách đánh giá hiệu và hợp lý hơn.
Một số thư viện phổ biến triển khai thuật toán boosting trong Python:
- XGBoost (Extreme Gradient Boosting): được thiết kế tối ưu về tốc độ và hiệu năng, phù hợp cho cả bài toán hồi quy và phân loại.
- LightGBM (Light Gradient Boosting Machine): sử dụng thuật toán học dựa trên cây (tree-based learning) và đặc biệt hiệu quả với tập dữ liệu lớn.
Cả hai thư viện trên đều giúp nâng cao độ chính xác, nhất là khi xử lý dữ liệu phức tạp hoặc nhiễu. LightGBM sử dụng một kỹ thuật đặc biệt gọi là Gradient-based One-Side Sampling (GOSS) để lọc các mẫu dữ liệu quan trọng cho việc tìm điểm chia (split points), từ đó giảm đáng kể chi phí tính toán. Việc kết hợp nhiều kỹ thuật tổ hợp học tập giúp loại bỏ giới hạn của từng mô hình riêng lẻ, mang lại kết quả vượt trội trong các bài toán khoa học dữ liệu.
4. Các Bước Hoạt Động Của Thuật Toán Gradient Boosting
Dưới đây là quy trình từng bước mô tả cách hoạt động của thuật toán Gradient Boosting:
4.1. Khởi tạo
Thuật toán bắt đầu bằng cách sử dụng một tập dữ liệu huấn luyện để thiết lập mô hình ban đầu, gọi là mô hình học cơ sở – thường là một cây quyết định (decision tree). Các dự đoán ban đầu của mô hình này thường được tạo ngẫu nhiên. Cây quyết định lúc này thường chỉ bao gồm một số nút lá (leaf nodes) hoặc nút kết thúc (terminal nodes) nhất định. Do dễ hiểu và dễ diễn giải, các mô hình yếu này được xem là lựa chọn tối ưu để khởi đầu, tạo nền móng cho những bước tiếp theo.
4.2. Tính Sai Số Dư
Với mỗi mẫu trong tập huấn luyện, hệ thống sẽ tính sai số dư (residual error) bằng cách lấy giá trị thực trừ đi giá trị dự đoán. Bước này giúp xác định những điểm mà mô hình hiện tại chưa dự đoán chính xác, từ đó làm cơ sở để cải thiện trong các bước tiếp theo.
4.3. Điều Chỉnh Bằng Kỹ Thuật Chuẩn Hóa
Sau khi tính sai số, trước khi huấn luyện mô hình tiếp theo, thuật toán áp dụng kỹ thuật chuẩn hoá (regularization) để giảm mức độ ảnh hưởng của mô hình mới trong toàn bộ hệ thống. Việc điều chỉnh này giúp kiểm soát tốc độ học của thuật toán và giảm thiểu hiện tượng quá khớp (overfitting), đồng thời tối ưu hiệu suất tổng thể của mô hình.
4.4. Huấn Luyện Mô Hình Kế Tiếp
Sử dụng các giá trị sai số dư được tính ở bước trước làm nhãn mục tiêu, mô hình mới hoặc mô hình yếu sẽ được huấn luyện để dự đoán chính xác các sai số này. Bước này tập trung vào việc sửa các lỗi mà mô hình trước đã mắc phải, từ đó cải thiện độ chính xác tổng thể của dự đoán.
4.5. Cập Nhật Tổ Hợp Học Tập
Sau khi huấn luyện mô hình mới, hệ thống sẽ đánh giá hiệu suất của tổ hợp hiện tại (gồm mô hình mới) trên một tập dữ liệu kiểm thử riêng (holdout set). Nếu kết quả đạt yêu cầu, mô hình mới sẽ được tích hợp vào hệ thống; nếu không, có thể cần điều chỉnh lại các siêu tham số (hyperparameters).
4.6. Lặp Lại
Các bước đã trình bày ở trên sẽ được lặp lại nhiều lần tùy theo nhu cầu. Mỗi vòng lặp sẽ tiếp tục xây dựng và tinh chỉnh mô hình cơ sở thông qua việc huấn luyện thêm các cây quyết định mới (decision trees), từ đó nâng cao độ chính xác của mô hình. Khi tổ hợp mô hình sau cùng đạt được độ chính xác mong muốn so với mô hình ban đầu (baseline model), quá trình có thể chuyển sang bước tiếp theo.
4.7. Tiêu Chí Dừng
Thuật toán sẽ kết thúc khi đạt một trong các tiêu chí dừng được xác định trước, như số vòng lặp tối đa, độ chính xác mục tiêu, hoặc khi hiệu quả cải thiện bắt đầu giảm dần (diminishing returns). Bước này giúp đảm bảo mô hình cuối cùng đạt được sự cân bằng hợp lý giữa độ phức tạp và hiệu suất.
5. Phương Pháp Kết Hợp (Ensemble Methods) và Kỹ Thuật Xếp Chồng (Stacking)
Việc kết hợp Gradient Boosting với các thuật toán học máy khác thông qua phương pháp kết hợp (ensemble methods) hoặc kỹ thuật xếp chồng (stacking) có thể giúp nâng cao độ chính xác trong dự đoán. Chẳng hạn, việc kết hợp Gradient Boosting với Support Vector Machines (SVMs), Random Forests, hoặc k-Nearest Neighbors (KNN) cho phép tận dụng thế mạnh riêng của từng mô hình, từ đó tạo ra một hệ thống dự đoán mạnh mẽ và ổn định hơn.
Xếp chồng (Stacking) là kỹ thuật huấn luyện nhiều mô hình cơ sở đồng thời, sau đó sử dụng kết quả đầu ra của các mô hình này làm đầu vào cho một mô hình tổng hợp (meta learner) – mô hình này sẽ học cách kết hợp các dự đoán để đưa ra dự đoán cuối cùng.
6. Dừng Sớm (Early Stopping) và Kiểm Định Chéo (Cross-validation)
Theo dõi hiệu suất mô hình trong quá trình huấn luyện và áp dụng kỹ thuật dừng sớm (early stopping) là cách hiệu quả để tránh hiện tượng quá khớp (overfitting). Cụ thể, quá trình tăng cường sẽ được dừng lại khi hiệu suất trên tập dữ liệu kiểm định (validation set) không còn được cải thiện hoặc bắt đầu giảm sút. Bên cạnh đó, việc sử dụng các chiến lược kiểm định chéo (cross-validation) như k-fold cross-validation giúp đánh giá hiệu suất mô hình một cách toàn diện hơn. Điều này không chỉ tăng độ tin cậy của quá trình đánh giá mà còn hỗ trợ hiệu quả trong việc tinh chỉnh siêu tham số (hyperparameter tuning) – từ đó nâng cao năng lực dự đoán của thuật toán Gradient Boosting.
7. Xử Lý Tập Dữ Liệu Mất Cân Bằng (Addressing Imbalanced Datasets)
Gradient Boosting khá nhạy cảm với tình trạng mất cân bằng lớp (class imbalance) – khi số lượng mẫu thuộc một lớp chiếm ưu thế hơn nhiều so với các lớp còn lại. Điều này có thể dẫn đến các dự đoán thiên kiến (bias), ưu ái lớp chiếm đa số.
Một số kỹ thuật có thể áp dụng để khắc phục:
- Tăng cường lớp thiểu số
- Giảm mẫu từ lớp chiếm đa số
- Sử dụng hàm mất mát có trọng số (weighted loss function) để gán mức phạt cao hơn cho lỗi xảy ra ở lớp thiểu số, từ đó buộc mô hình phải học kỹ hơn các mẫu ít gặp
Áp dụng các biện pháp này kết hợp với việc tinh chỉnh siêu tham số hợp lý, thuật toán Gradient Boosting có thể đạt được độ chính xác cao hơn và khả năng khái quát tốt hơn, ngay cả trong những bài toán phức tạp như phân tích dữ liệu đa chiều hay theo dõi môi trường phức tạp.
8. Ứng Dụng Của Thuật Toán Gradient Boosting
Gradient Boosting có nhiều ứng dụng thực tế trong nhiều lĩnh vực khác nhau. Dưới đây là một vài ví dụ:
Xử lý dữ liệu y tế đa chiều (high-dimensional medical data):
Gradient Boosting có khả năng xử lý hiệu quả các bộ dữ liệu có số lượng đặc trưng (features) lớn hơn rất nhiều so với số lần quan sát (observations). Ví dụ, trong chẩn đoán y khoa, thuật toán này có thể được sử dụng để phát hiện bệnh dựa trên dữ liệu bệnh nhân – vốn có thể bao gồm hơn 100 đặc trưng đầu vào. Nhờ sử dụng các cây quyết định (decision trees) làm mô hình yếu, Gradient Boosting có thể xử tốt bài toán dữ liệu đa chiều (high dimensionality) – điều mà các mô hình hồi quy tuyến tính truyền thống (linear regression models) thường gặp khó khăn. Bên cạnh đó, thuật toán này cũng có khả năng khai thác thông tin giá trị từ dữ liệu thưa (sparse data), giúp nó trở thành lựa chọn phù hợp cho các ứng dụng như tin sinh học (bioinformatics) hoặc phân loại văn bản (text classification).
Giảm tỷ lệ rời đi của khách hàng:
Khi một mô hình đã có sẵn nhưng hiệu suất chưa đạt kỳ vọng, Gradient Boosting có thể được sử dụng để liên tục cải thiện kết quả bằng cách điều chỉnh sai lệch từ các lần dự đoán trước đó. Ví dụ, trong lĩnh vực viễn thông, doanh nghiệp có thể sử dụng mô hình hồi quy logistic (logistic regression) để dự đoán tỷ lệ rời đi của khách hàng (customer churn). Tuy nhiên, hiệu quả có thể chưa cao. Việc áp dụng thuật toán Gradient Boosting cho phép phát hiện các yếu tố quan trọng dẫn đến việc khách hàng rời đi, như tần suất cuộc gọi cao hoặc chất lượng mạng kém. Việc tích hợp những yếu tố này vào mô hình không chỉ giúp cải thiện độ chính xác mà còn hỗ trợ giảm tỷ lệ khách hàng rời đi một cách hiệu quả hơn.
Kết Luận
Qua bài viết này, THPT Hồng Ngự 1 hy vọng bạn đã hiểu rõ hơn về gradient là gì toán học và vai trò của nó trong thuật toán Gradient Boosting. Đây là một công cụ mạnh mẽ trong học máy, có khả năng giải quyết nhiều bài toán phức tạp trong các lĩnh vực khác nhau. Việc nắm vững kiến thức về gradient và các thuật toán liên quan sẽ giúp bạn tiến xa hơn trong hành trình khám phá khoa học dữ liệu.
Có thể bạn quan tâm
- In Stock Là Gì? Tìm Hiểu Khái Niệm Quan Trọng Trong Bán Lẻ
- Áo Ngực Size 36 Là Bao Nhiêu Cm?
- Tin Tức KJC – Cập Nhật Thông Tin Nhịp Đập Giải Trí Toàn Cầu
- 12 Cung Hoàng Đạo Là Ai Trong Sakura?
- CIB Là Gì? Giải Đáp Chi Tiết Về CIB Trong Ngân Hàng MB Bank
- 1999 Là Bao Nhiêu Tuổi?
- Acc role là gì? Tìm hiểu về Acc role trên mạng xã hội
- 2004 Mệnh Gì Hợp Màu Gì? Giải Đáp Chi Tiết Cho Tuổi Giáp Thân
- Treatment Da Là Gì: Khám Phá Retinoids và Tretinoin
- 1998 Là Tuổi Gì? Giải Đáp Chi Tiết Về Tuổi Mậu Dần